
Mastering the Nepali Board Game of Bagh Chal with self-learning AI

People have long dreamed of creating machines that can think and decide for themselves. There have been countless Sci-Fi books and movies that exploit (and sometimes over hype) the term "Artificial Intelligence". This peculiar trait of the human mind — to imagine something well before it comes into existence — has itself led to many inventions and discoveries. Just a decade ago, the research on Artificial Intelligence was limited to only a few candidates pursuing higher degrees in Universities or big companies. The increase in computational power and data availability over the past few years, however, has made it possible for anyone with a decent computer to get started with Machine Learning (ML) and Artificial Intelligence (AI). This blog discusses one such personal project that I started working on almost a year ago. The project tries to use state-of-the-art methods in the deep reinforcement learning paradigm to master the traditional Nepali board game of Bagh Chal through self-play.
Instead of diving straight into the project, I want to take some time to introduce Artificial Intelligence and some of its relevant concepts. If you would like to skip these upcoming sections, directly refer to the Bagh Chal AI Project section.
Renaissance of Artificial Intelligence
When programmable computers were first created, they rapidly overtook humans in solving problems that could be described by a list of formal mathematical rules, such as crunching numbers. The main obstacle to computers and artificial intelligence proved to be the tasks that are easy for human beings but difficult to formalize as a set of mathematical rules. The tasks such as recognizing spoken words or differentiating objects in images require intuition and do not translate to simple mathematical rules.
We generally do not give our brain enough credit and are unaware of the extent to which our intuition plays a role in our everyday thinking process. To that, I want to start the blog with a perfect example that Andrej Karpathy gave in his blog back in 2012 that holds to this day.

The above picture is funny.
What does your brain go through within fractions of seconds to comprehend this image? What would it take for a computer to understand this image as you do?
- You recognize it is an image of a bunch of people in a hallway.
- You recognize that there are 3 mirrors, so some are “fake” replicas of people from different viewpoints.
- You recognize Obama from the few pixels that make up his face.
- You recognize from a few pixels and the posture of the man that he is standing on a scale.
- You recognize that Obama has his foot on top of the scale (3D viewpoint) from a 2D image.
- You know how physics works: pressing on the scale applies force to it and will hence over-estimate the weight of the person.
- You deduce from the person's pose that he is unaware of this and further infer how the scene is about to unfold. He might be confused after seeing that the reading exceeds his expectations.
- You perceive the state of mind of people in the back and their view of the state of mind of the person. You understand why they find the person's imminent confusion funny.
- The fact that the perpetrator here was the president maybe makes it even funnier. You understand that people in his position aren't usually expected to undertake these actions.
This list could go on and on. The mind-boggling fact is that you make all these inferences just by a glance at a 2D array of RGB values. Meanwhile, even the strongest of the supercomputers would not even come close to achieving this feat using today's state-of-the-art techniques in Computer Vision.
For the sake of this blog, let's start with something much simpler. Imagine that you are given a task to identify handwritten digits in a 28x28 image. How would you go about solving this problem? It might sound ridiculously easy at the start considering that even a small child introduced to numbers can get this correct almost every time. Even though this example is used as the typical "Hello, World!" program for people getting into Artificial Intelligence (especially deep learning), the solution to this problem is not as trivial as it first seems.
One obvious and non-machine learning approach would be to use handcrafted rules and heuristics on the shape of strokes to distinguish the digits. However, due to the variability of handwriting, it leads to a proliferation of rules and exceptions giving poor results. Some sample variants of the handwritten digits are shown in the following image.

So, how would we tackle this problem the ML/AI way?
Before we start talking about how to solve this problem, let's first understand how ML/AI differs from the plain old definitive programmatic or algorithmic approach. Machine learning refers to the concept that allows computers to learn from examples or experiences rather than being explicitly programmed.
Basically, we trade-off the hard-coded rules in the program for massive amounts of data. Mathematical tools in linear algebra, calculus, and statistics are cleverly used to find patterns in the data and construct a model that is then used for prediction. A training process occurs where the model is improved iteratively by evaluating the quality of its prediction. Over time, the model learns to correctly predict over the data that it has never seen before.
For instance, instead of using handcrafted rules to identify handwritten digits, we can show the computer a bunch of examples of how each digit looks like. It creates a model that learns from all these example data and over time learns to generalize the shape of each digit.
Creating a model, evaluating the performance of the model, and improving the model is a topic for another blog. However, let's have a quick glance at the sub-fields of machine learning.
The Sub-Fields of Machine Learning
Supervised Learning
Supervised learning is a type of machine learning in which the learning is done from the data having input and output pairs. The goal is to create a model that learns to map from the input values to the output.
It is called supervised learning because we know beforehand what the correct answers are. The goal of the machine learning algorithm is to learn the relationship between each input value to the output value by training on a given dataset. In doing so, the model should neither prioritize specific training data nor generalize too much. To avoid this, a larger training dataset is preferred and the model is tested using input values that the model has never seen before (test dataset).
This is better understood with an example. Suppose you're given the following dataset:
| x | 0 | 2 | 3 | 4 |
| y | 0 | 4 | 9 | 16 |
Let's put your admirable brain to use, shall we? Can you construct a mental model to find the function that maps x to y?
After quick speculation, you might have stumbled upon the function y = x2 that fits the dataset perfectly.
Now let's see how our hunch would have changed if we had access to only a portion of the dataset:
| x | 0 | 2 |
| y | 0 | 4 |
Here, both y = 2x and y = x2 are equally plausible answers. But we know that the actual answer is y = x2, and y = 2x is considered to be the underfit model due to less training samples. Our model would predict y = 6 for x = 3 while the actual answer is y = 9.
Let's look at some visualizations to clearly understand these concepts.
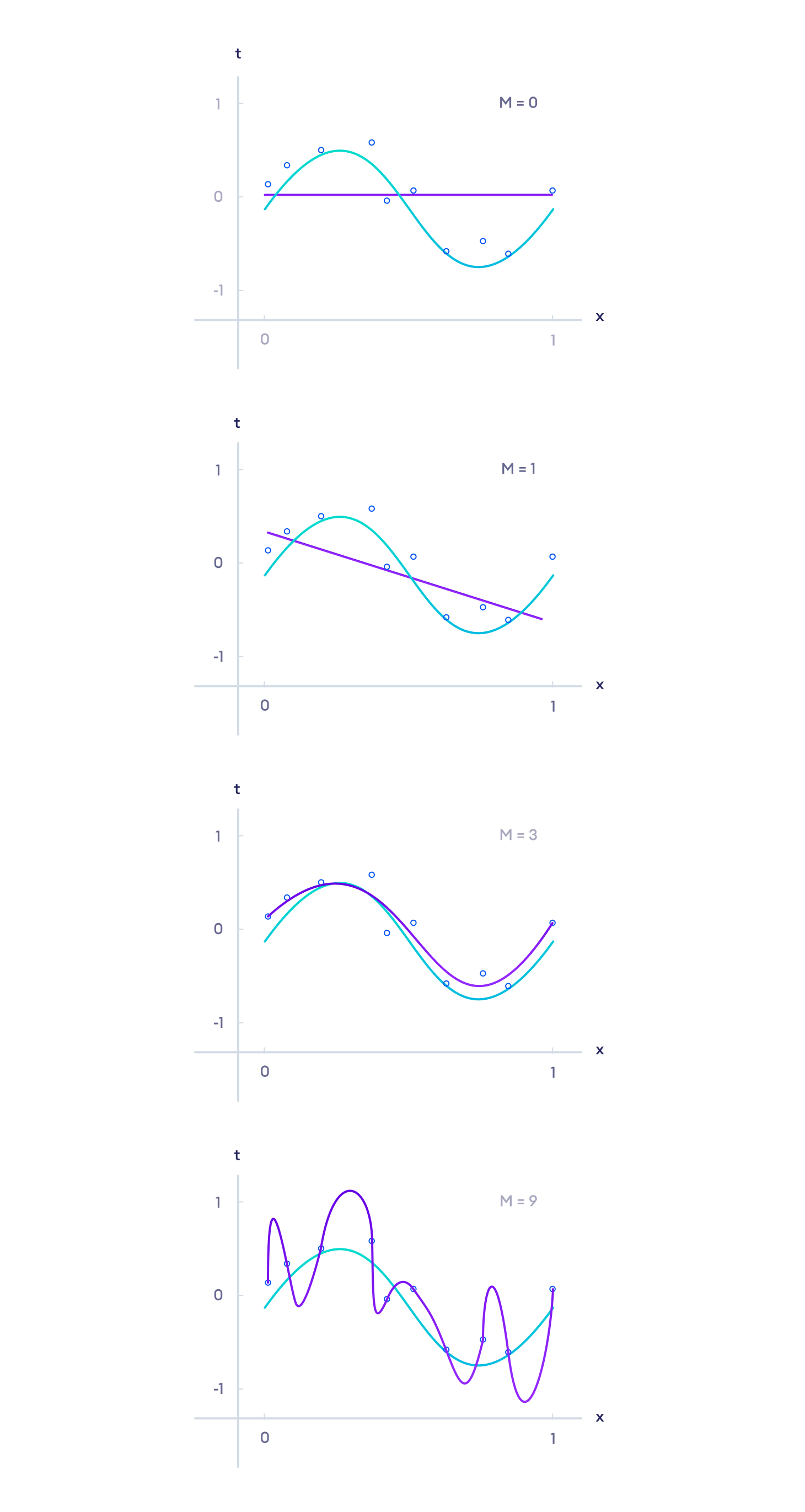
Here, the blue line shows the actual function and the purple line shows the prediction of the model. The blue circles represent the training set.
We can see that the last model correctly predicts all the training data (all points pass through the purple line). However, this model is said to be an overfit model (too specific to the training set) and it performs badly on the test set. Similarly, the first two models are said to be underfit models (too much generalization).
The third model is the best among these models even though it has a lesser accuracy than the overfitted model. The model can further be improved by using more training data as shown below.

Supervised learning can further be divided into classification and regression.
Classification problems are related to making probabilistic estimates on classifying the input data into one of many categories. Identifying handwritten digits falls under this category.
Regression problems are related to predicting real value output in continuous output space. The above problem of finding the best-fit polynomial to predict output to its other input values falls under this category.
To learn more about supervised learning, visit Introduction to Supervised Learning.
Unsupervised Learning
Unsupervised learning is a type of machine learning in which the learning algorithm does not have any labels. Instead, the goal of unsupervised learning is to find the hidden structure in the input data itself and learn its features.
Some types of unsupervised learning include clustering, dimensionality reduction, and generative models.
Clustering is the method by which the input data is organized into clusters based on the similarity on some of their features and their dissimilarity with other clusters, despite having no labels.
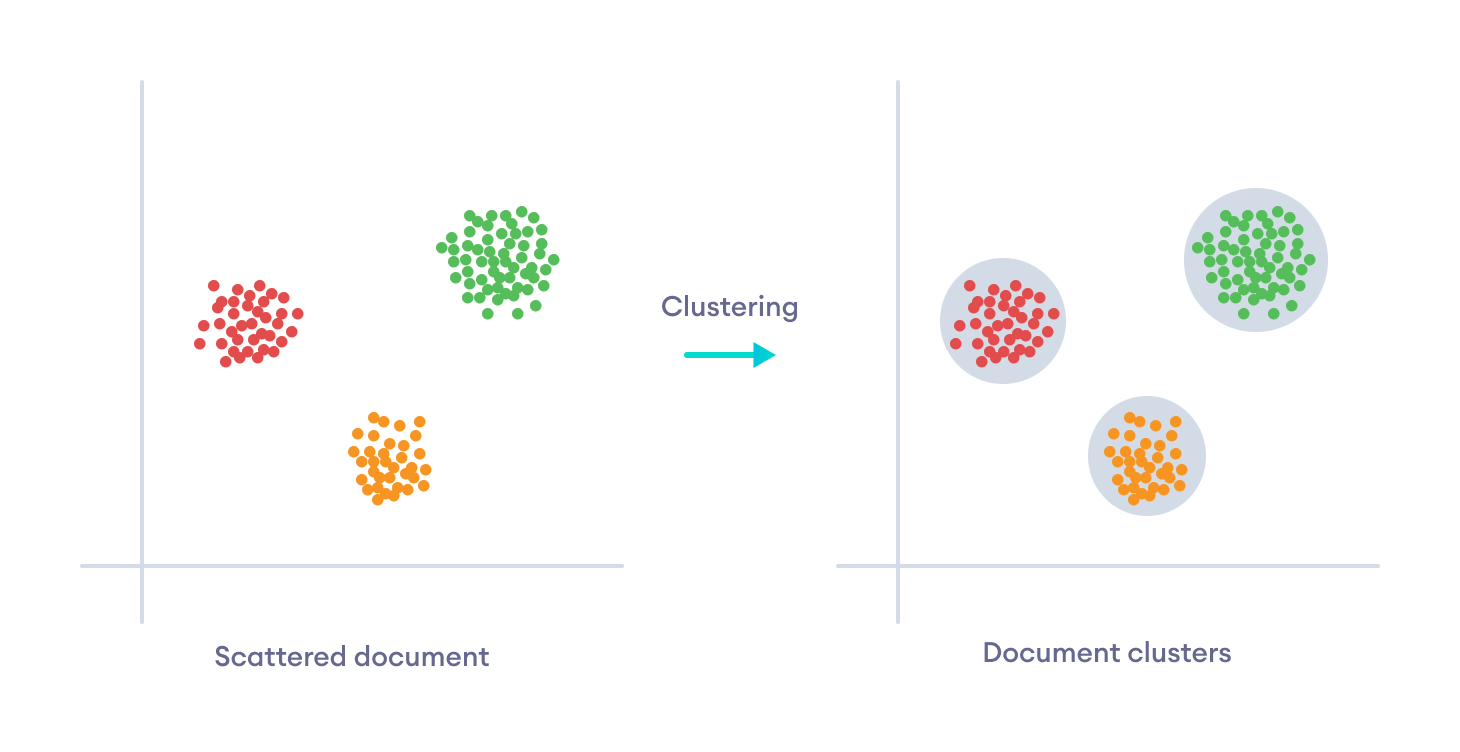
Dimensionality reduction is used to convert a set of data in higher dimensions to lower dimensions. They can remove redundant data and only preserve the most important features. This pre-processing technique can reduce a lot of computational expenses and make the model run a lot faster.
The new unsupervised deep learning field has given rise to autoencoders. Autoencoders use deep neural networks to map input data back to themselves. The twist is that the model has a bottleneck as a hidden layer. So, it learns to represent the input in a smaller amount of data (compressed form).

Generative modeling is a task that involves learning the regularity or patterns in the input data so that the model can generate output samples similar to the input dataset.
Since my project does not use unsupervised learning, we won't go into its details in this blog. Check out the following to learn more about unsupervised learning:
- Machine Learning For Humans – Unsupervised Learning
- Unsupervised Learning and Data Clustering
- Generative Models
Reinforcement Learning
Reinforcement Learning (RL) is the type of Machine Learning where an agent learns how to map situations to actions so as to maximize a numerical reward signal from the environment.
The typical examples where RL is used are:
- Defeat the world champion at Go
- Make a humanoid robot walk
- Play different Atari games better than humans
- Fly stunt maneuvers in a helicopter
It also is the main component of my AI project that we later are going to discuss.
So what makes reinforcement learning different?
- There is no supervisor, only a reward signal
- Feedback may be delayed and not instantaneous
- Agent’s actions affect the subsequent data it receives
At any time step, the agent in state S1 takes an action A1. Based on this action, the environment provides the agent with reward R1 and a new state S2.
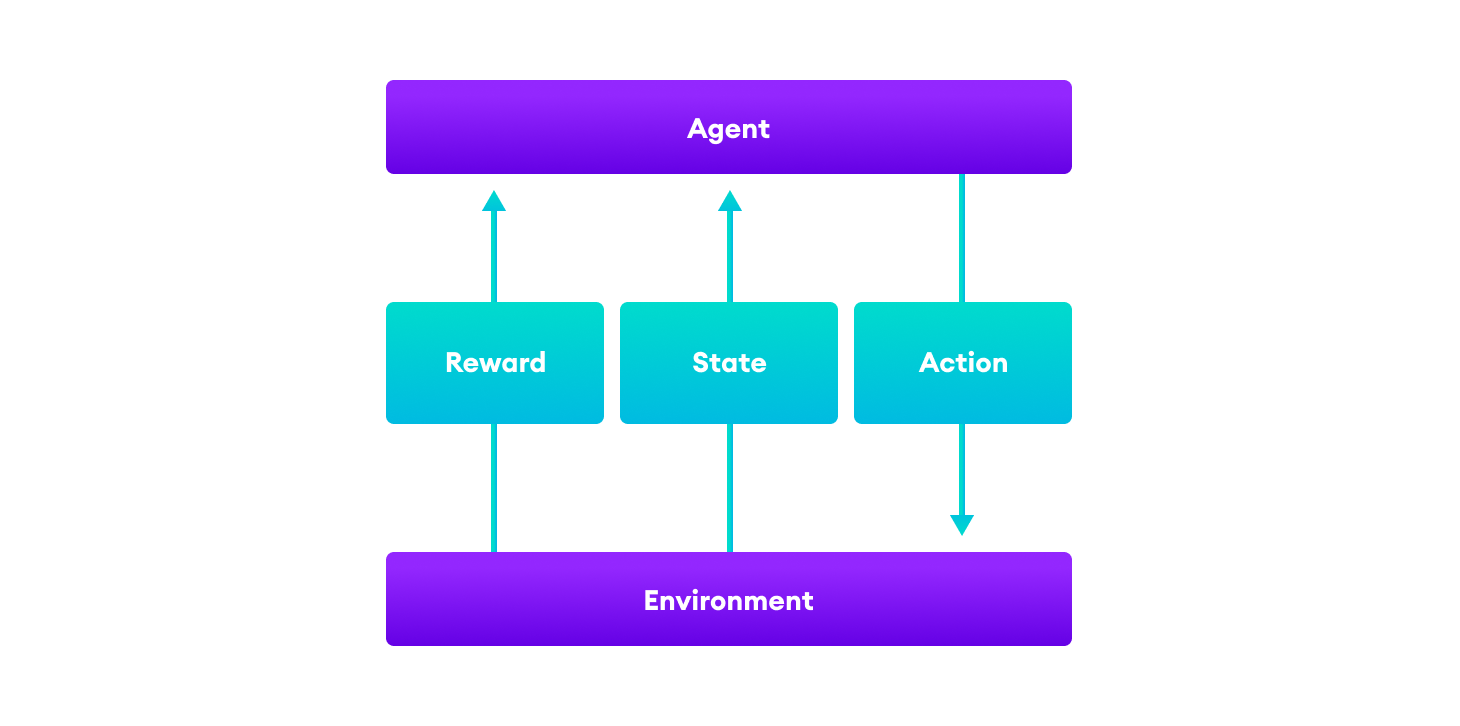
A reward is a scalar feedback signal which indicates how well an agent is doing. The agent's goal is to maximize the reward signal. For instance, in the example of flying stunt maneuvers in a helicopter,
- A positive reward may be given for following the desired trajectory.
- A negative reward may be given for crashing.
Major Components of an RL Agent
- Policy: A function that defines the behavior of the agent.
- Value function: The agent's understanding of how good each state and/or action is.
- Model: The agent’s representation of the environment.
What makes the reinforcement learning problem so much harder is that the agent will initially be clueless about how good or bad its actions are. Sometimes, even the environment might be only partially observable. The agent has to perform hit and trial until it starts discovering patterns and strategies.
Moreover, the agent cannot act greedily on the reward signal. The agent has to learn to maximize the reward signal in the long term. So, sometimes the agent must be willing to give up some reward so as to gain more rewards in the long run. One such example would be to sacrifice a piece in chess to gain a positional or tactical advantage.
The exploration vs exploitation trade-off is the central problem in RL where the agent with incomplete knowledge about the environment has to decide whether to use strategies that have worked well so far (exploitation) or to make uncertain novel decisions (exploration) in hopes to gain more reward. To learn more about Exploration vs Exploitation and some solutions, visit Intuition: Exploration vs Exploitation.
Some classical solutions to the reinforcement learning problem are Dynamic Programming, Monte Carlo Methods, and Temporal-difference learning. You can visit RL Course by David Silver to learn more about reinforcement learning problems and solutions.
David Silver was the lead researcher on AlphaGo and AlphaZero.
AlphaGo was the first computer program to beat a professional human Go player and the first to defeat a Go world champion. It was first trained on professional human games and then learned to improve by itself. To learn more, read the AlphaGo Research Paper.
AlphaZero was an improved and more general version of AlphaGo that learned to play Go, Chess and Shogi without any human knowledge. It surpassed its predecessor and defeated AlphaGo 100-0 in 100 games of Go. To learn more, read the AlphaZero Research Paper. My self-learning AI project is also inspired very closely by AlphaZero.
Deep Learning
Numerous artificial intelligence projects have tried to hard-code knowledge about the world in formal languages. This approach is known as the knowledge base approach to AI. However, none of these projects have led to major breakthroughs.
Then, machine learning was introduced so that the AI systems could acquire their own knowledge from the data. The performance of these simple machine learning algorithms depends heavily on the representation of the data and the use of important features.
Imagine that we have developed a logistic regression model (regression for binary data such as True or False) to detect Diabetic Retinopathy (diabetes complication that affects eyes). To use this model, a doctor has to manually observe the retina image and put relevant pieces of information into the model, such as the number and type of retinal lesions (damaged regions) and where they appear in the image.
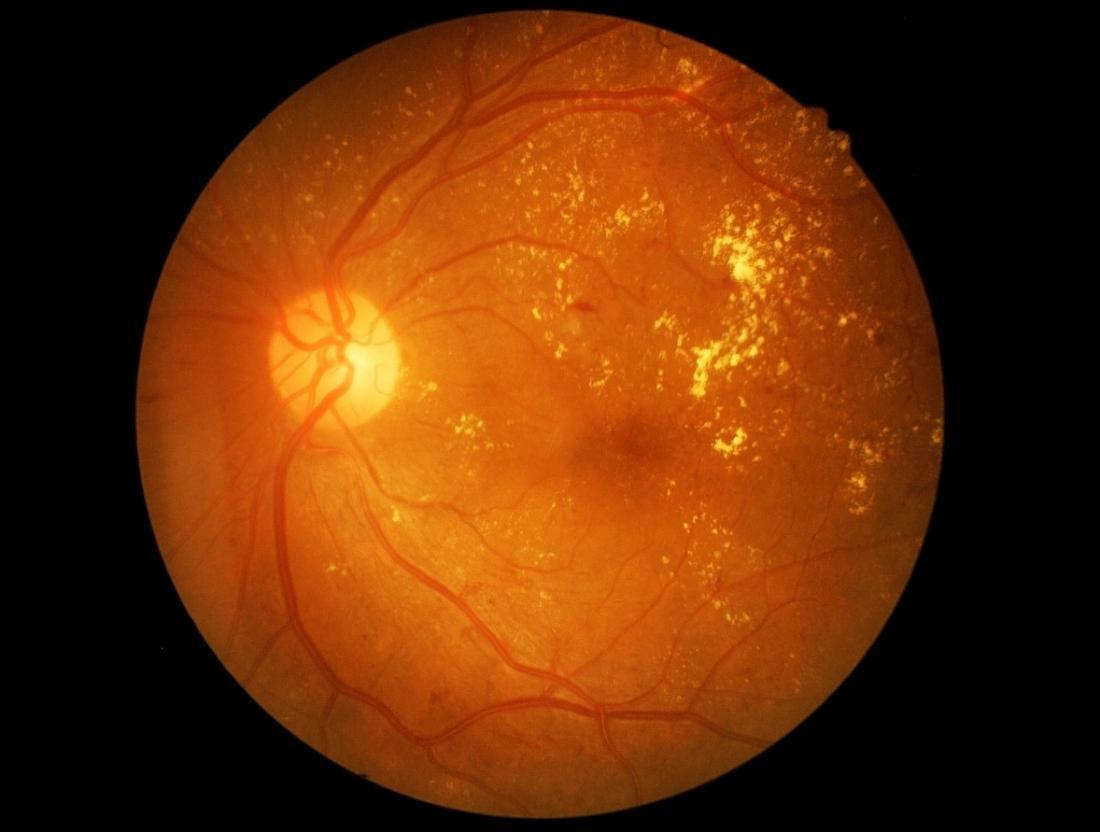
If the model was directly given the retina image as shown above, rather than the formalized report from the doctor, it would not be able to make predictions. It is because the individual pixels of the retina image have a negligible correlation with the presence or absence of Diabetic Retinopathy.
Let's look at one more example where the representation of the data plays an important role in the performance of the ML model.
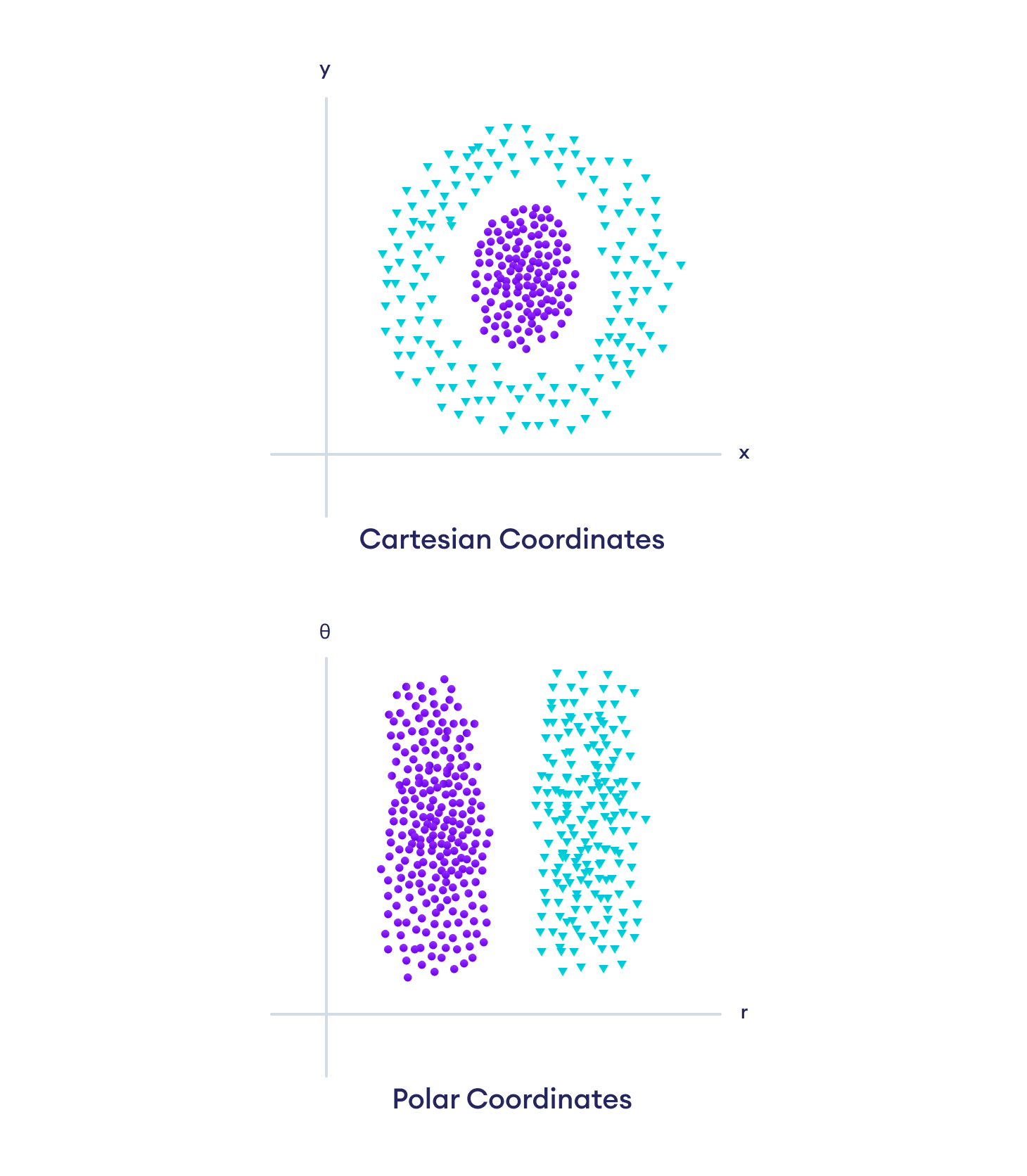
Here, it is impossible to separate the two sets of data in cartesian coordinates with a linear model. However, just changing the representation of data to polar coordinates makes this task an easy one.
For many tasks, it is actually very difficult to know what features should be extracted. Suppose we want to write a program that detects cars in images. Since cars have wheels, we might like to use their presence as a feature. However, it is embarrassingly difficult to describe wheels in terms of pixel values. Even though wheels have simple geometric shapes, the real-life images of wheels are complicated by shadows, glaring sunlight, masking of the wheels by other objects, and so on.
One solution to the problem of finding the right feature is representation learning. In this approach, the human intervention is further reduced by replacing the hand-designed features with learned representations by the model itself.
In other words, the model not only learns the mapping from features to the output but also learns to choose the right features from the raw data.
Whenever we go from one technique to another, we substitute one problem for another one. Now, the major challenge in representation learning is to find a way for the model to learn the features by itself. However, it is very difficult to extract high level, abstract features from raw data directly. This is where deep learning comes to the rescue.
Deep Learning is a type of representation learning where the representations are expressed in terms of other simpler representations. This allows the computer to build complex features from simpler features.
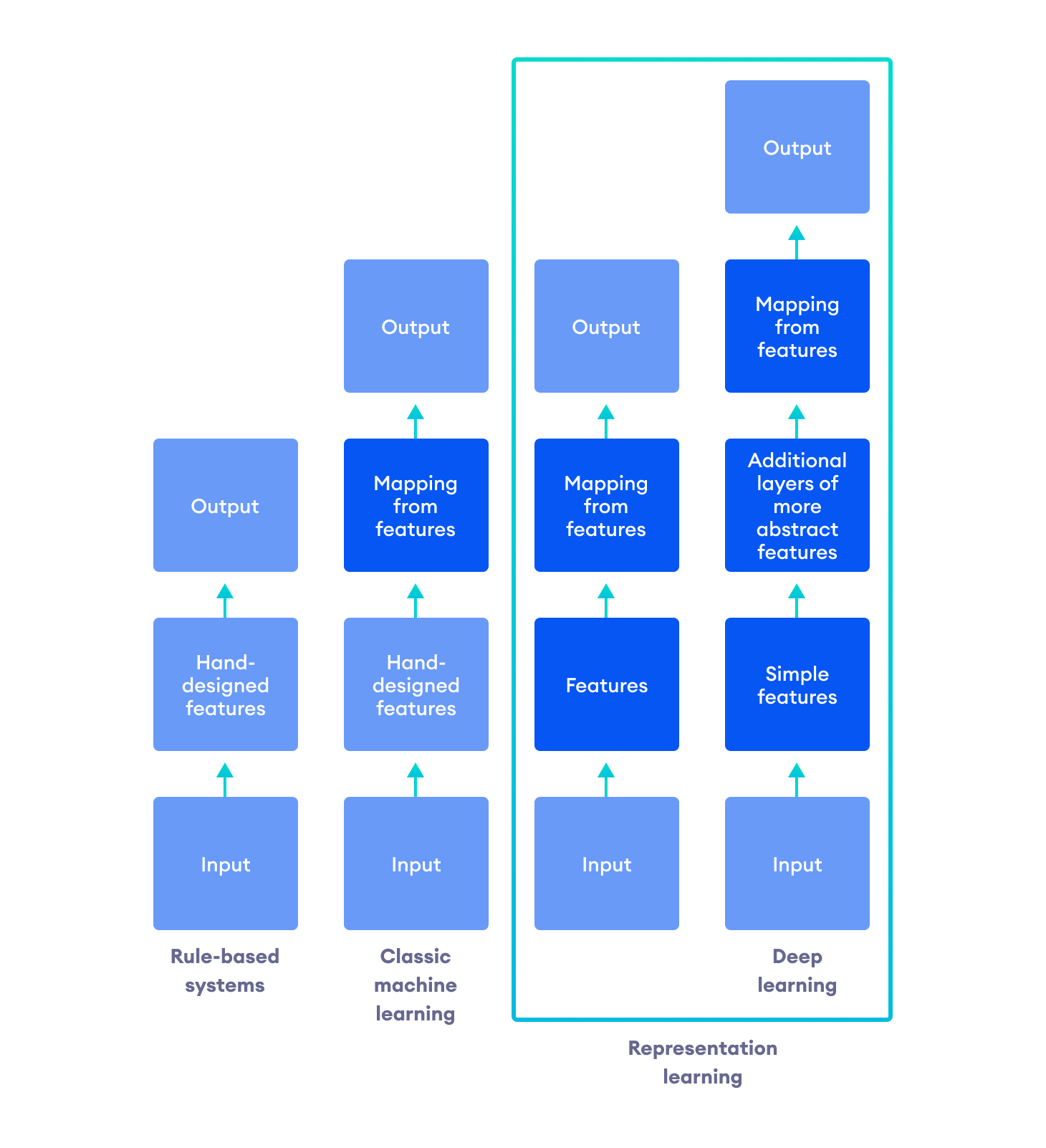
The quintessential example of a deep learning model is the multilayer perceptron that maps the input to the output. Let's look at an illustration of how a deep learning model learns to recognize complex patterns by building upon simpler concepts in the data.
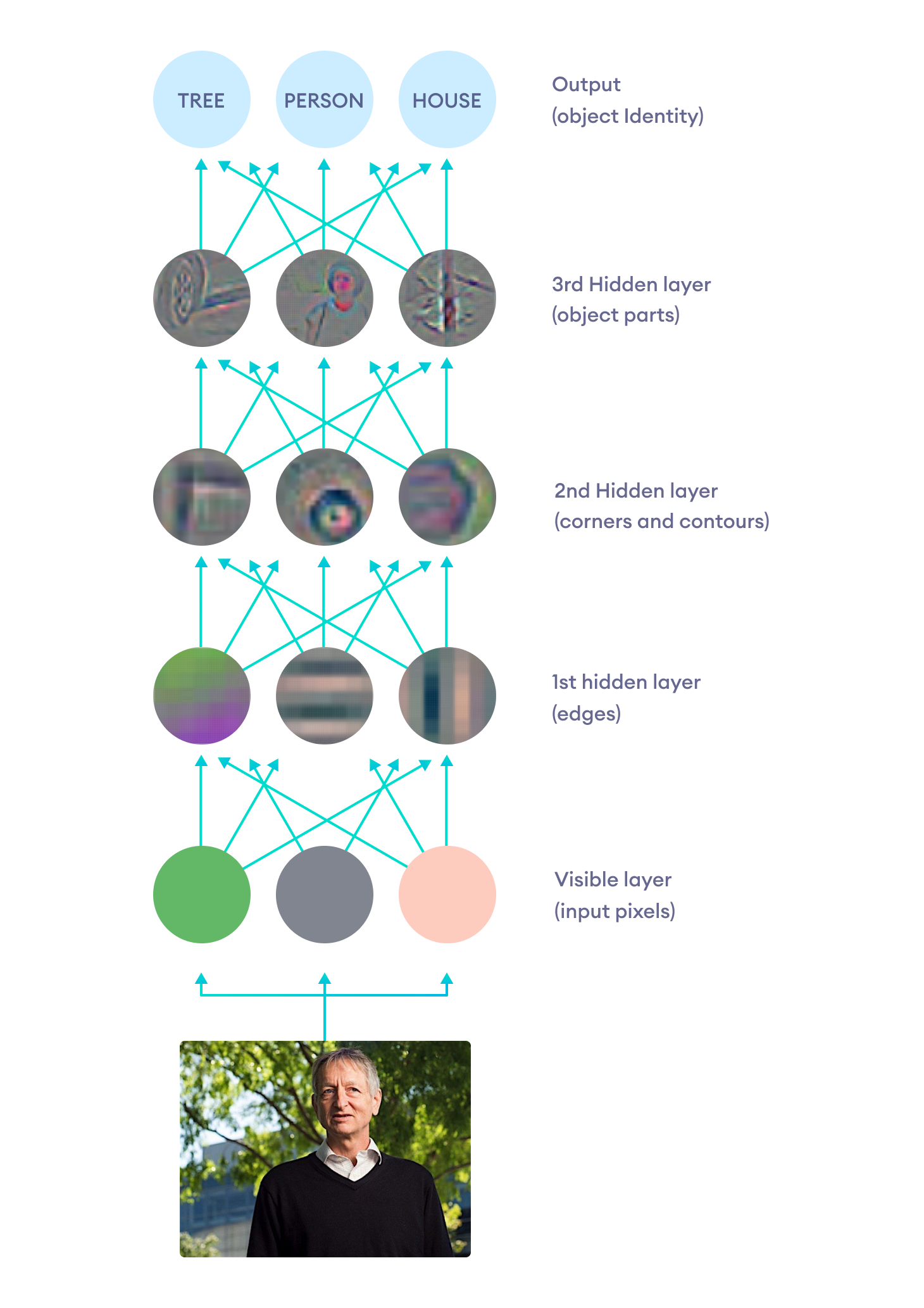
Even though each pixel value of the image has no correlation with identifying the object in the image, the deep learning model builds a hierarchical structure to learn representations. It first learns to detect edges that makeup corners and contours which in turn gives rise to the object parts. These object parts are then finally able to detect the object in the image.
The examples above are inspired by the ones in the Deep Learning book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Visit Deep Learning Book Website to read a free online version of the book. It is an excellent material to get started with Deep Learning.
Project Alpha BaghChal?
The motivation behind the project
Back in the summer of 2017, I had a few months break before starting my junior year in high school. At that point, I was not new to programming but I barely had any idea about Artificial intelligence (AI). I wanted to understand how chess engines like Stockfish (not an AI engine) work, but soon found myself in AI territory once I heard about AlphaZero. That instantly got me into ML/AI and I spent almost two years starting from scratch and working on smaller projects.
Inspired by AlphaZero, I thought of making a chess engine but the complexity of the game and the amount of training it would require set me back even before I got started. During my senior year, I tried making a similar engine as a science fair project but for a much simpler game of Bagh Chal. Even then, I had underestimated the difficulty of the project and the time scramble led to the project failure without yielding any results. I stopped working on it for a while until I finished high school and gave it another shot.
Before discussing how reinforcement learning and deep learning was used in the agent's architecture, let's first acquaint ourselves with the game of Bagh Chal. In the upcoming sections, I will also discuss how I built a game library and introduced game notations to record the moves for this traditional and somewhat obsolete game.
Bagh Chal
Bagh Chal is one of the many variants of the tiger hunting board games played locally in South East Asia and the Indian subcontinent. This ancient Nepali game shares many resemblances to other traditional games like Komikan, Rimau, and Adugo in terms of board structure and player objectives.
The strategic, two-player board game is played on a 5x5 grid. The pieces are positioned at the intersection of the lines where adjacent lines from the intersection define the legal moves for a piece.
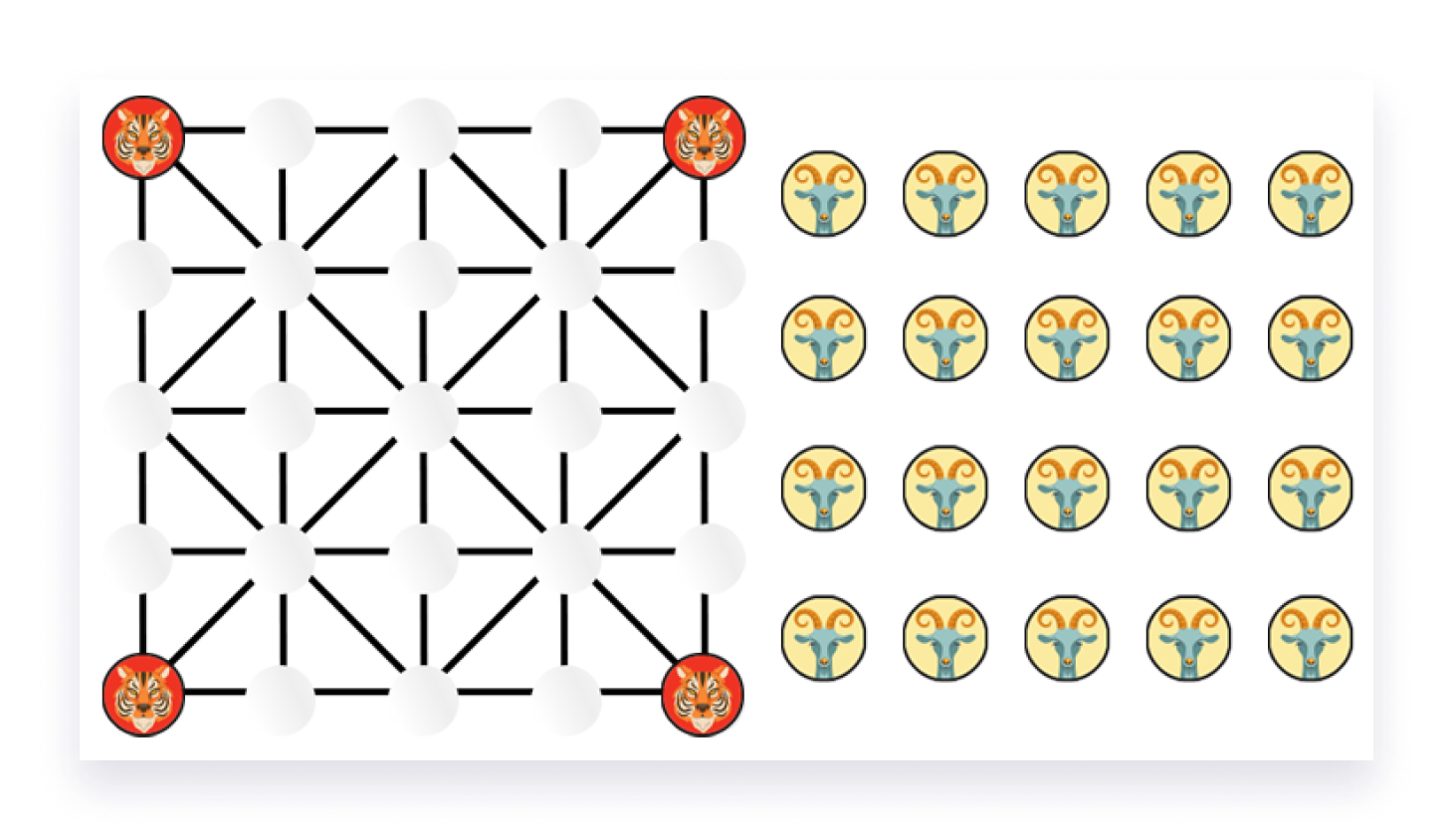
Game Rules
The game completes in two phases:
- Goat Placement phase
During the placement phase, twenty goats are placed one after the other in one of the empty slots on the board while tigers move around. Goats are not allowed to move until all goats have been placed. - Goat Movement phase
The movement phase continues with both players moving their corresponding pieces.
Pieces can move from their corresponding slot to other empty slots along the grid lines.
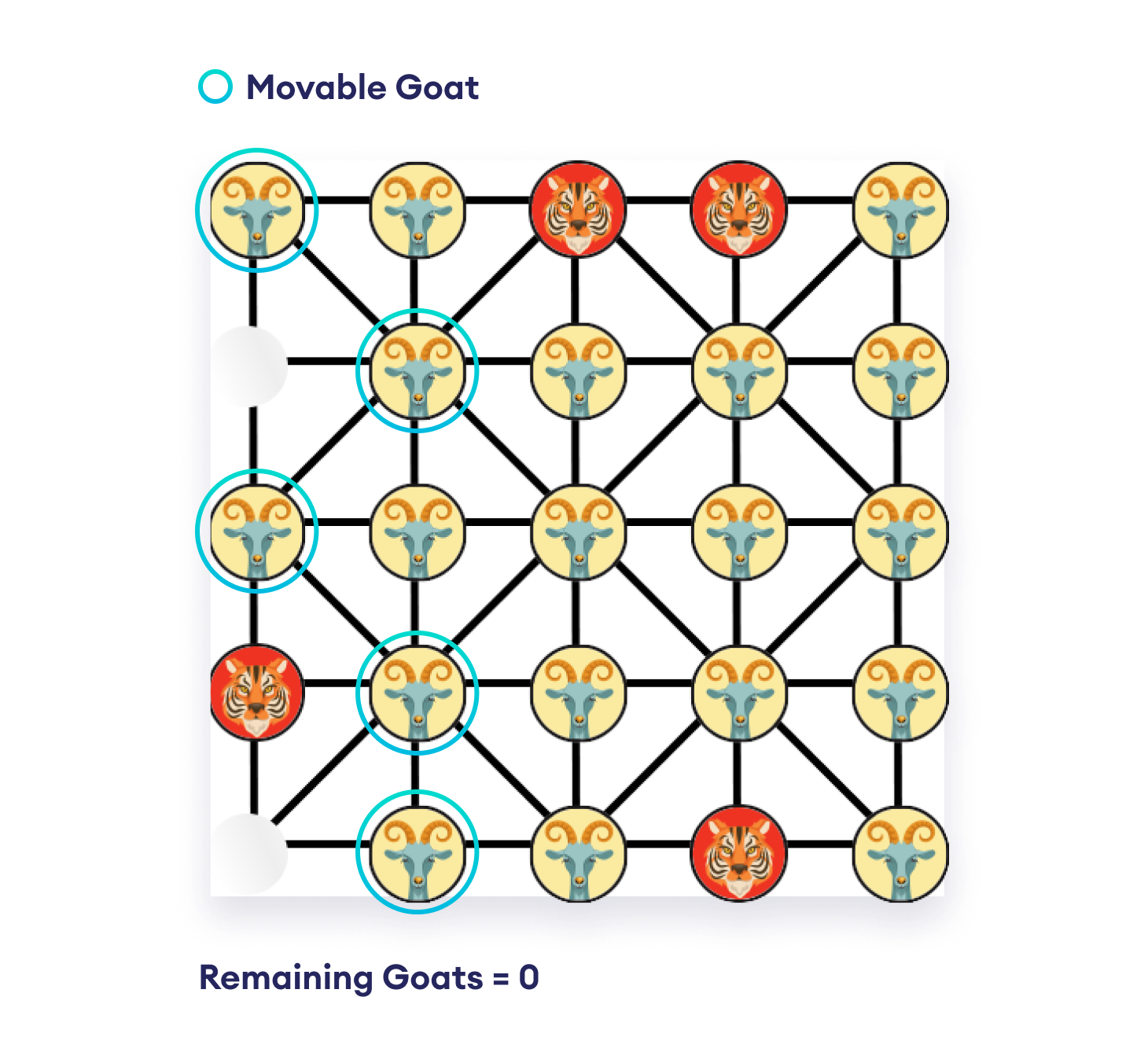
Throughout the game, tigers also have a special Capture move, where they can jump over a goat along the grid lines to an empty slot, thereby removing the goat from the board.
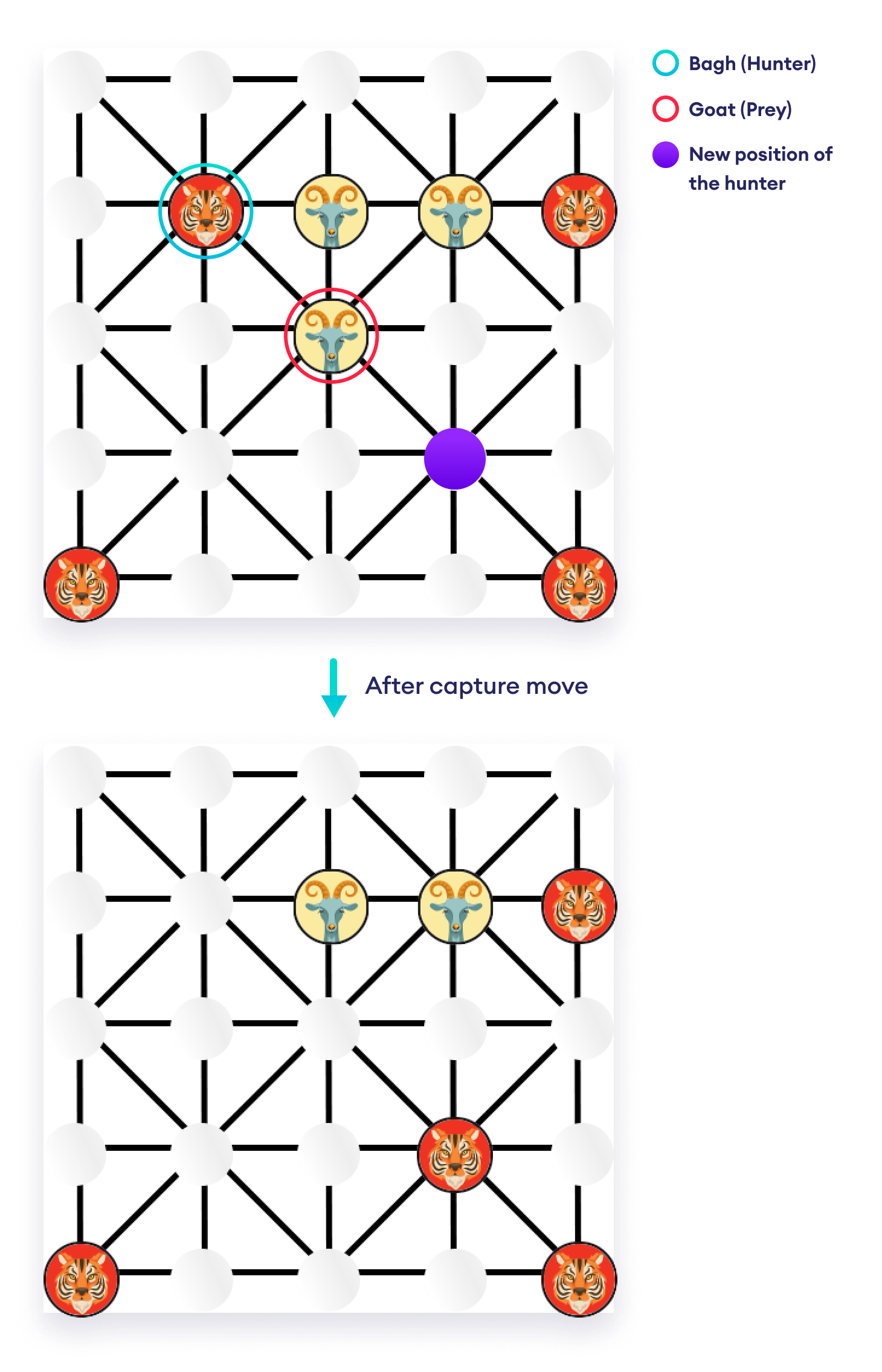
This asymmetric game proceeds with tigers trying to capture goats and goats trying to trap tigers (without any legal moves). The game is over when either the tigers capture five goats or the goats have blocked the legal moves for all tigers. In some rare cases, tigers can also win by blocking all the legal moves for goats.
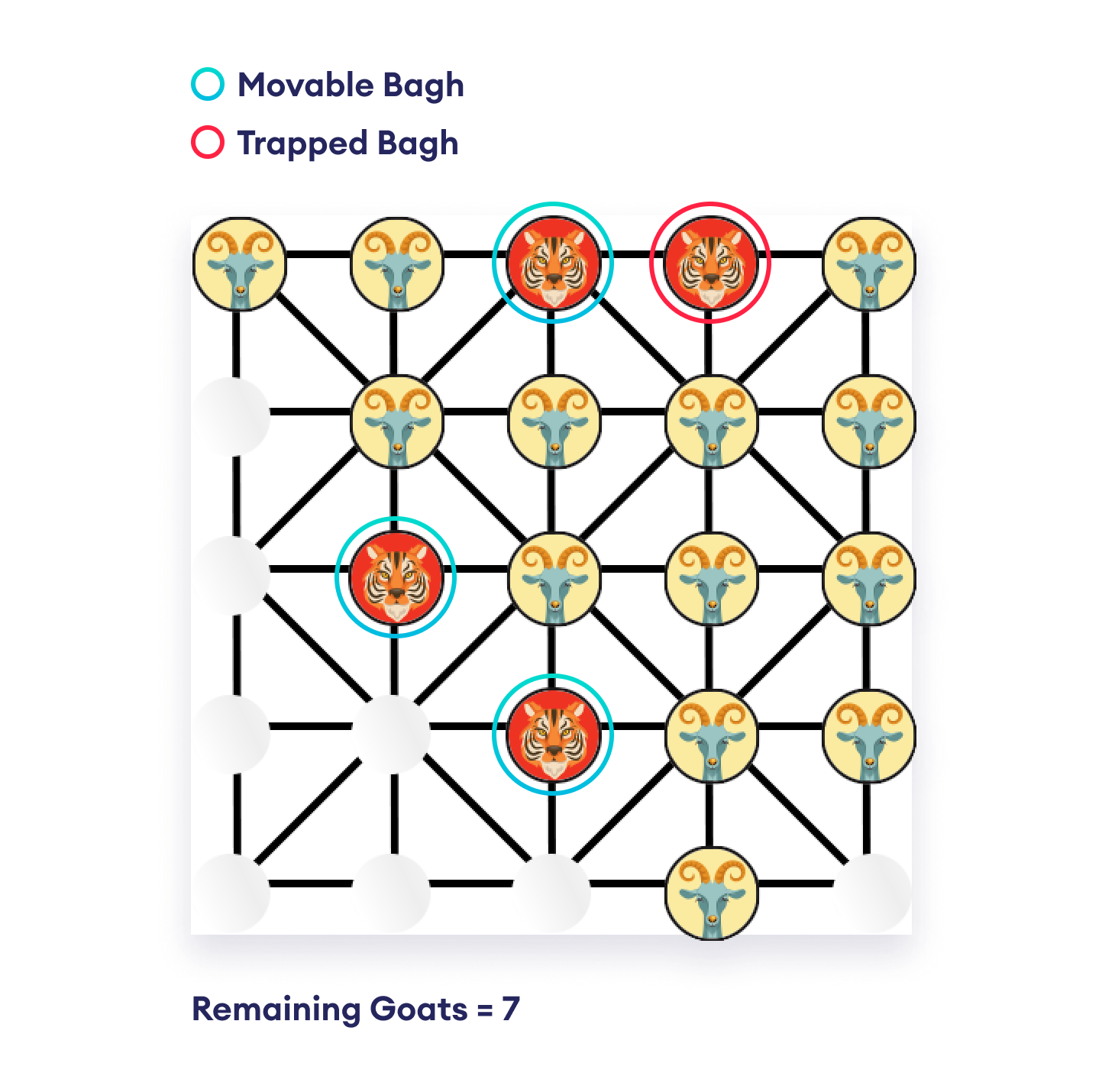
Ambiguous Rules
The game can fall into a cycle of repeating board positions during the gameplay. To deal with these perpetual move orders that goats can employ to defend themselves from being captured, some communities have introduced constraints that do not allow moves that revert the game position to one that has already occurred in the game.
However, this restriction can sometimes prevent moves that are forced for bagh players or cause goats to make absurd sacrifices. The board positions are bound to reoccur in lengthy games where there have been no capture moves for a long time. Thus, declaring a winner on that basis is highly ambiguous.
For this project, this rule has been overridden by the standard "draw by threefold repetition" rule, where the recurrence of the same board position for three times automatically leads to a draw. The rule is rational as the recurrence of board position implies that no progress is being made in the game.
Creating Bagh Chal library (Game Environment)
Before working on the AI project, I had to prepare a Python Bagh Chal library to use the logic of the game and keep records of the board game states.
baghchal is a pure Python Bagh Chal library that supports game import, move generation, move validation, and board image rendering. It also comes with a simple engine based on the minimax algorithm and alpha-beta pruning.
Visit the GitHub baghchal Repository to learn more about this library.
Introducing Game Notation
Since Bagh Chal is a traditional Nepali board game, there was no recorded game dataset nor was there any way to keep track of the game moves.
So, I used two notations to record Bagh Chal games: PGN and FEN.
Portable Game Notation (PGN) is inspired by the game of chess. This notation consists of a full move history of the game, along with other information. The algebraic notation used makes PGN easier for humans to read and write, and for computer programs to parse the information.
The history of games is tracked by movetexts, which defines actual moves in the game. Each goat move and tiger move constitutes a movetext pair, where goat piece and tiger (Bagh) piece are represented by "G" and "B" respectively. Moves are defined in the following ways:
- Placement move: G<new[row][column]>
For example: G22 - Normal move: <Piece><old[row][column]><new[row][column]>
For example: B1122 - Capture move: Bx<old[row][column]><new[row][column]>
For example: Bx1133
Note: Both the row and column position use numbers rather than an alphabet and a number like in chess because Bagh Chal has reflection and rotational symmetry, so the numbers can be counted from any direction.
At the end of the game, # is added along with:
- 1-0 for Goat as the winner.
- 0-1 for Tiger as the winner.
- 1/2-1/2 for a draw.
The following PGN represents one entire Bagh Chal game:
1. G53 B5545 2. G54 B4555 3. G31 B5545 4. G55 B1524 5. G15 B2414 6. G21 B1413 7. G12 B1322 8. G13 B2223 9. G14 B4544 10. G45 B4435 11. G44 B5152 12. G43 B5251 13. G52 B3534 14. G35 B1122 15. G11 B3433 16. G25 B2324 17. G23 B3334 18. G41 B5142 19. G51 B2232 20. G33 Bx2422 21. G1524 B2223 22. G1122# 1-0
FEN (Forsyth–Edwards Notation) for Bagh Chal tracks only the current board position, current player, and the number of moves made. Even though it does not contain the full history of moves, it encapsulates enough information to continue the game from that point onwards and is helpful for shorthand representation of the board state. It consists of 3 fields:
- Piece location
The piece location is given for each row, separated by "/". Like PGN, "B" and "G" represent Tigers and Goats. The integers [1-5] represent empty spaces between the pieces. - Player to move
The player with next move, given by "G" or "B" - Number of moves made by Goats
This integer represents the number of half moves in the game. This is required to track the number of remaining and captured goats.
The following FEN represents the starting Bagh Chal board state:
B3B/5/5/5/B3B G 0
Prior Work on Bagh Chal
Bagh Chal is a relatively simple board game in terms of game tree complexity, compared to other board games like Go, Shogi, or Chess. The Bagh Chal programs found online use search algorithms based on variants of the Minimax algorithm such as Alpha-beta pruning to traverse the game tree.
Prior works have been done to evaluate the game under optimal play and even exhaustively analyze the endgame phase of the game using retrograde analysis. In their book called Games of No Chance 3, authors Lim Yew Jin and Jurg Nievergelt even prove that Tigers and Goats is a draw under optimal play.
My project, on the other hand, is inspired by AlphaZero, a general reinforcement learning agent by Google DeepMind. Instead of creating an agent that uses brute-force methods to play the game, the project takes a different route where the agent learns to improve its performance by continually playing against itself. It uses a single deep residual convolutional neural network which takes in a multilayered binary board state and outputs both the game policy and value, along with Monte Carlo Tree Search.
Let's look at what each of these terms means and how they fit into the design of AI architecture.
Design of the AI agent
Before proceeding, why not first look at the end performance of the Bagh Chal AI agent that we are going to design next?
The sections below assume that you know following topics. If not, visit the corresponding links to read about them in brief.
- Convolutional Neural Network (CNN)
CNN is a type of neural network especially used in image recognition as it considerably reduces the parameters and makes the network more efficient. To learn more, visit A Comprehensive Guide to Convolutional Neural Networks. - ResNets (Residual Blocks)
It is difficult to train deep neural networks due to exploding or vanishing gradients. Residual blocks optimize the training of these deep networks by introducing skip connections in the network. To learn more, visit Introduction to ResNets. - Monte-Carlo Tree Search (MCTS)
MCTS a probabilistic and heuristic driven game tree search algorithm that combines tree search with reinforcement learning. After each simulation, it learns to selectively explore moves rather than applying brute-force methods. To learn more, visit Monte Carlo Tree Search. - Batch Normalization
Batch normalization reduces the covariant shift (amount by which values shift) in the units of the hidden layer. To learn more, visit Batch normalization in Neural Networks.
In the past, deep convolutional neural networks served as board evaluation functions for searching game trees. AlphaZero — the quintessential deep reinforcement learning agent for board games — takes this approach one step further by using Policy-Value networks and Monte Carlo Tree Search algorithm.
Similar to AlphaZero, the BaghChal AI agent's neural network fΘ(s) = (p, v) takes in the current board state and gives out two outputs, a policy vector pΘ(s) and a scalar value estimate vΘ(s).
- The scalar value v estimates the expected outcome of the game from the given position (which player is most likely to win from that point on). It represents the agent's positional understanding of the game.
- The policy vector outputs a vector of move probabilities p with components pa = Pr(a|s) for each action a. They serve as 0-ply strategies, since they do not perform any look-ahead and thus correspond to intuitive play, previously thought to be exclusive only to human players.
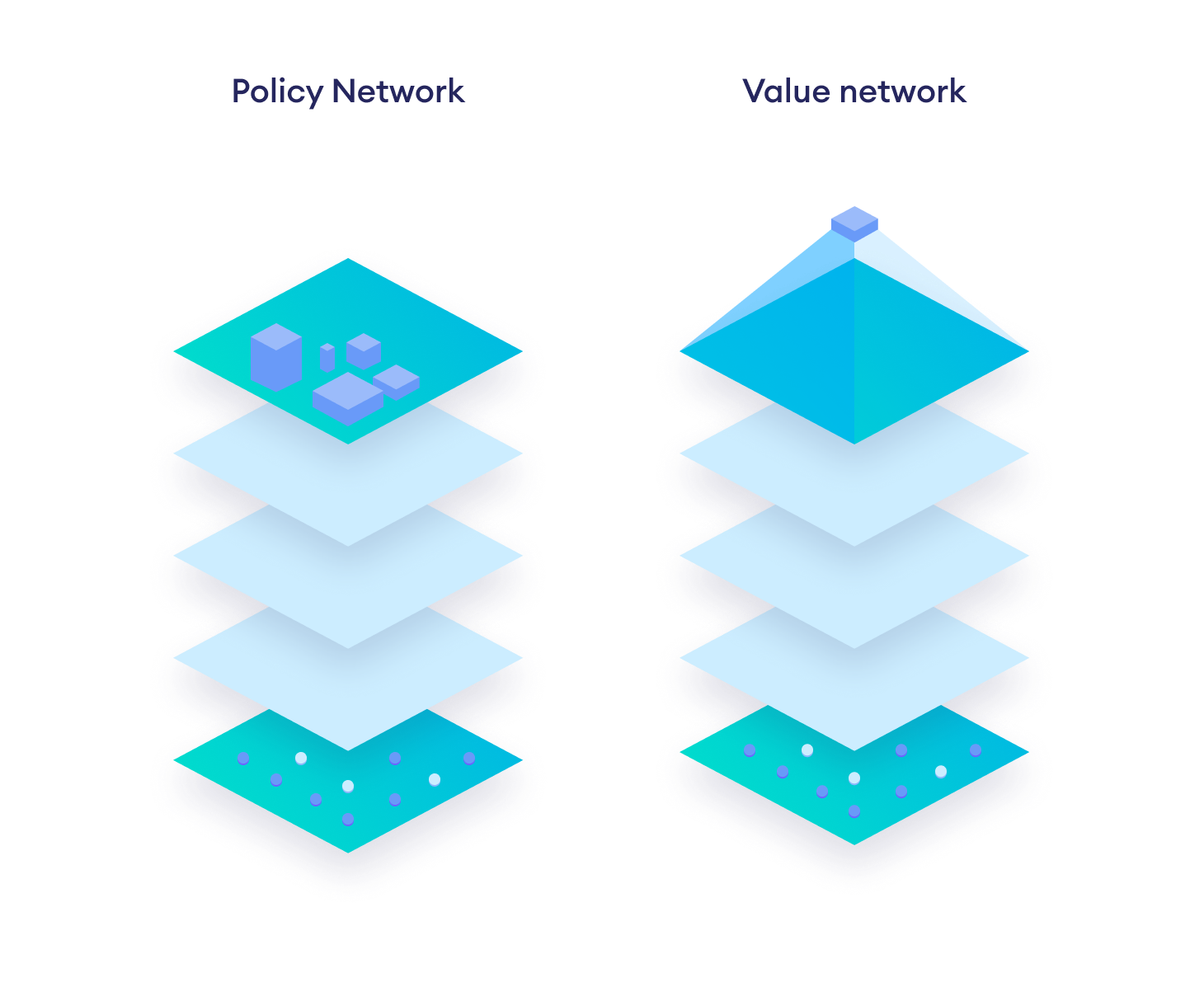
A number of simulations are played out from the root (current position) to a leaf node, employing Monte Carlo tree search (MCTS) algorithm that utilizes raw output from the neural network to selectively explore the most promising moves. Evaluation from the MCTS are then used to improve parameters of the neural network. This iterative relation between the neural network and tree search allows the agent to start from the ground up and continually get stronger from self-play, after every iteration.
The network is initially set to random weights and thus, its predictions at the beginning are inherently poor. As the search is conducted and parameters are improved, the previous poor initial judgement of the network is overridden, making the agent stronger.
Note that the Monte Carlo Tree Search used in the Bagh Chal AI is not a pure MCTS where random rollouts are played once the search tree hits a leaf node. Instead, this random rollout is replaced by the value estimate from the neural network. Watch the AlphaZero MCTS Video Tutorial to learn about the complete Monte Carlo Tree Search Algorithm used in AlphaZero.
Network Architecture
As previously mentioned, the AI agent has a single neural network that has two heads: a policy and a value network.
The input is taken as 5x5x5 input stack which is different than in the AlphaZero architecture:
- The 1st layer represents the layer for Goat pieces (5x5 grid filled with 1 for presence of goat & 0 for absence of goat)
- The 2nd layer represents the layer for Tiger pieces (5x5 grid filled with 1 for presence of tiger & 0 for absence of tiger)
- The 3rd layer is a 5x5 grid filled with the number of goats captured.
- The 4th layer is a 5x5 grid filled with the number of tigers trapped.
- The 5th layer represents whose turn it is to play (filled with 1 for Goat to play and 0 for Tiger to play)
This input then goes through some residual blocks that have Convolutional, Batch Normalization and Activation layers. The neural network then branches off to two parts: one for policy network and the other for the value network. They both go through some fully-connected Dense layers.
The policy network outputs a 217 dimensional vector that represents all the moves that are possible in Bagh Chal at any point. It is a probability distribution for all moves and thus adds up to 1. It uses Categorical Cross-Entropy as the loss function.
The value network outputs a single scalar value between -1 (Represents Tiger player is winning) and 1 (Represents Goat player is winning). It uses Mean Squared error as the loss function.
All in all, the policy network combined with the MCTS helps in reducing the breadth of the tree search.
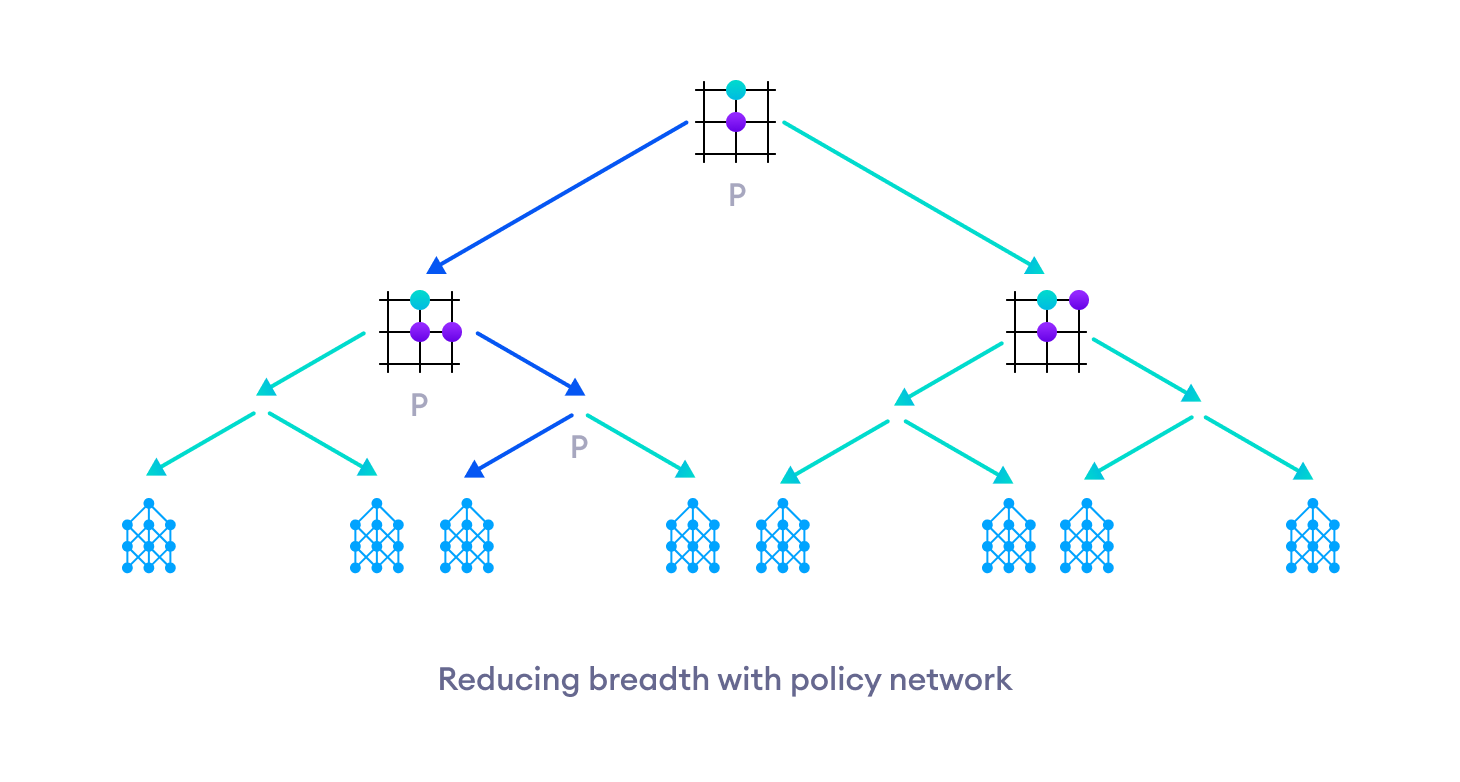
Similarly, the value network helps in reducing the depth of the tree search.

Training
For training, a number of games were played using the neural network employing MCTS and about 50 simulations for each move.
At the end of the game, 1 was awarded for Goat as winner, -1 was awarded for Tiger as winner and 0 for a draw. For all moves for that game, the value network was then trained to predict this number.
In MCTS, the most promising move is the one that was visited the most. So, the policy network was improved by training it to predict moves in proportion to the number of times the move was made in the simulation.
Similarly, the symmetry of Bagh Chal was used explicitly to populate the training set for each game.
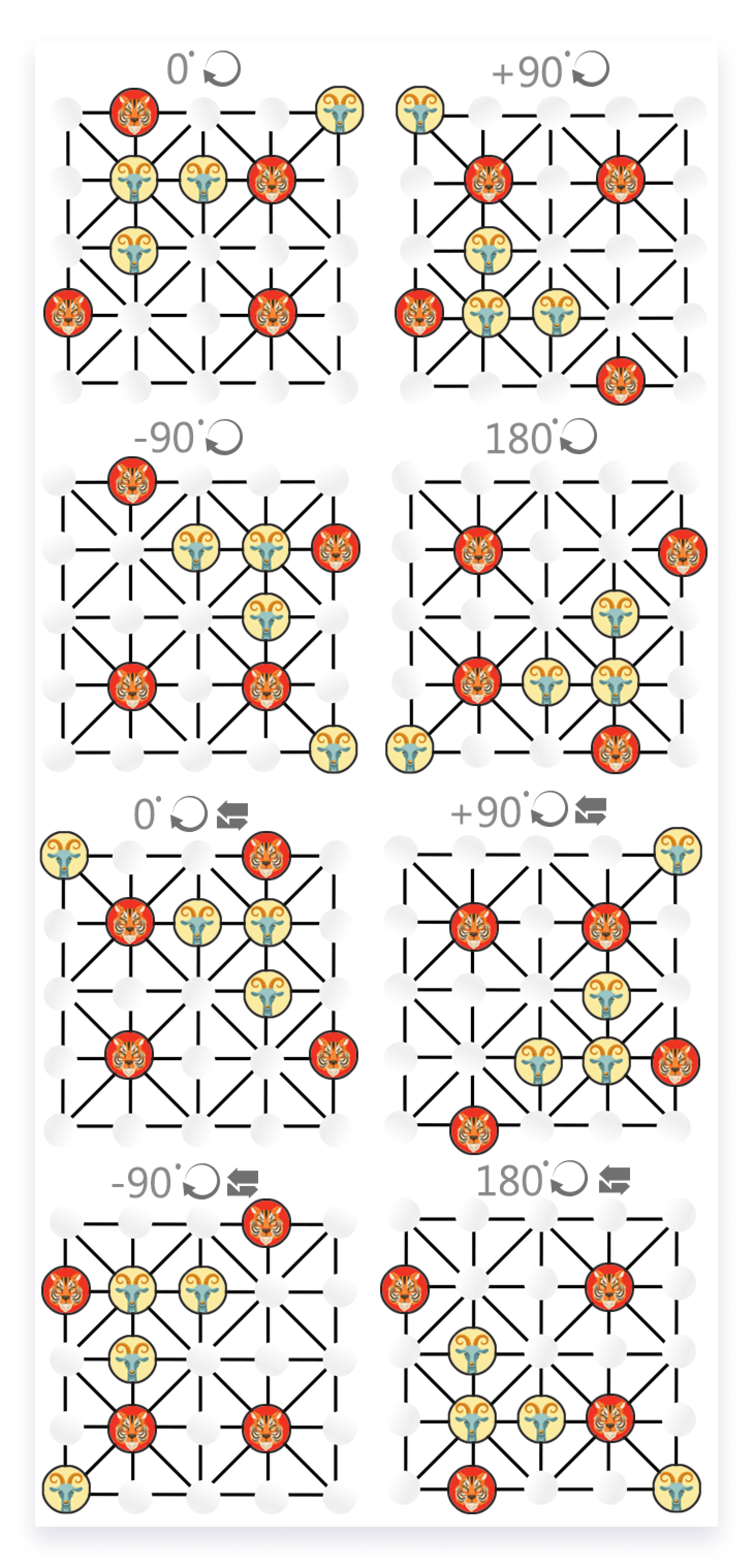
Here, we can see that one game can produce eight times more training sample games.
Compromising the Tabula Rasa Learning
Although all of this seems to work in theory, I did not experience any improvements in the agent's play even with some training. My speculation is that it might have been caused by the asymmetry of the game. Bagh Chal is an asymmetrical game as each player has different objectives.
If we were to make random moves (similar to the performance of an untrained Neural Network), the probability of Tiger winning the game is larger than the game ending in a draw than Goat winning the game. When the tree search reaches a terminal state favoring a given player very few times, there may not be enough actual game environment rewards for the tree-search to correct any poor network predictions. Thus, the agent gets stuck in a local optimum.
Even though this problem is solved as the model gets trained more and more, I had to find other solutions due to hardware limitations.
I eventually decided to use a greedy heuristic in the training pipeline by initially training the agent on games generated by minimax algorithm with alpha-beta pruning on depth 4.
Results
After training the agent for some time, first greedily on minimax generated games and then by making it play against itself, the agent learns to pick up on the strategies that humans use in their own games. One of the strategies is to always occupy the board corners as the Goat player and maintain distance between the Tiger pieces as the Tiger player.
This trained agent was then used to play games against itself, where most of the games ended in a draw. This result was consistent with the prior study that proves the game as a draw under optimal play. About 10 percent of the time, however, the Goat player was able to snatch victory.
Though this Bagh Chal AI agent punishes even slight inaccuracies by human players, it is by no means perfect. Occasionally, when the agent played as Goat against human players, it made absurd sacrifices over and over again. This represents gaps in the learning domain of the agent. It means that the agent reached positions that it had never explored during its training, and hence had no clue about certain positions.
The AI agent could have been further improved by:
- More Experimenting with the hyperparameters of the neural network (Network structure)
- Using two separate networks for Goats and Tigers
- Tabula Rasa Learning
- More training
If you want to learn more about the project and play around with its code, you can find one early prototype of this project in the GitHub AlphaBaghChal Repository.
Final Words
One key takeaway from this blog is that the performance of the Artificial Intelligence project boils down to finding the right set of data to train on and choosing the correct hyperparameters to get an optimal learning process.
As the potential of Artificial Intelligence continues to grow by the day, its scope has also broadened to encompass many other fields. Even if you are new to Artificial Intelligence or programming in general, you definitely won't regret keeping up with the field of AI.
Below are some resources that will help you stay up-to-date with the recent developments in AI:
Below are some online resources to play around with interesting AI models:
Subscribe to Programiz Blog!
Be the first to receive the latest tutorial from Programiz by signing up to our email subscription. Also more bonus like inside looks on the latest feature and many more.
